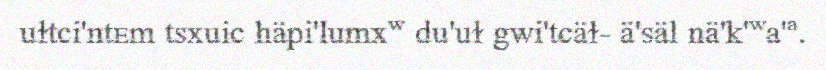Data
Gladys Reichard collected dozens of stories from the Coeur d'Alene (CdA) tribe. She transcribed them both by hand and typing them on a special keyboard for the language's orthography. All the documents had the CdA sentences above English.
My work focused on conducting OCR on the typed documents.
Challenges did arise with the documents as they were poorly scanned, typewriter mistakes, and noise.
All data used were in CdA and combination of an image of a line of text and another file with my best guess at the transcription.
Ground-Truths
Git Link350 actual screenshots from the various documents with accompanying transcriptions.
I measured the Zipf-Score and found it was high, with around 1.23 (Calculations done in survey_data.py). However, due to the rarity of some characters, it was difficult to capture it all. But I tried my best.
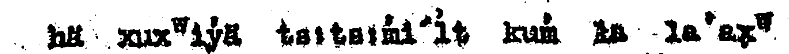
hä xuxʷiýä tsɩtsɩḿi'ĺt kuḿ ɫa la'ʷ
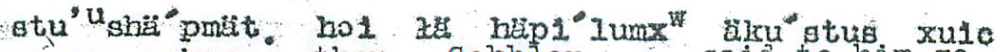
stu'ᵘshä'pmät. hɔi ɫä häpi'lumxʷ äku'stus xuic
Synthetic Data
1,000 'fake' data
Due to be a one-woman team, I hadn't the time to take a significant amount of ground-truth pairs. Because of that, I decided to create synthetic data using various Python scripts and packages found here
- Markovify: Using existing text, create novel words in the language using a Markhov chain model that captures patterns in existing words and recombines them Code
- Example words include: xʷä'ntc, q́ʷᴇńtsu,tcɩtśä'ᵃ̈
- Augraphy Allows you to alter images to add noise (blurriness, ink bleed, photocopy lines) Code
- Because Tesseract requires relatively clean images, I limited the amount of noise to just trying to replicate the typewriter like style
- Low Random Ink Lines: Adds ink lines randomly through the image
- Inkbleed: Captures all edges (ie letters) in the image and adds a slight blur
- Letterpress: Mimics uneven ink dispertion on the image
- Subtle Noise: Emulates the imperfections in scanning solid colors due to subtle lighting differences
- Pillow: Utilizing the Image functionality was able to create the images. Code